Integration of Kedro with MLflow as Kedro DataSet and Hooks (callbacks)¶
How to use MLflow from Kedro projects¶
Kedro DataSet and Hooks (callbacks) are provided to use MLflow without adding any MLflow-related code in the node (task) functions.
Kedro DataSet
pipelinex.MLflowDataSet(https://github.com/Minyus/pipelinex/blob/master/src/pipelinex/extras/datasets/mlflow/mlflow_dataset.py)Kedro Dataset that saves data to or loads data from MLflow depending on
datasetargument as follows.If set to “p”, the value will be saved/loaded as an MLflow parameter (string).
If set to “m”, the value will be saved/loaded as an MLflow metric (numeric).
If set to “a”, the value will be saved/loaded based on the data type.
If the data type is either {float, int}, the value will be saved/loaded as an MLflow metric.
If the data type is either {str, list, tuple, set}, the value will be saved/load as an MLflow parameter.
If the data type is dict, the value will be flattened with dot (“.”) as the separator and then saved/loaded as either an MLflow metric or parameter based on each data type as explained above.
If set to either {“json”, “csv”, “xls”, “parquet”, “png”, “jpg”, “jpeg”, “img”, “pkl”, “txt”, “yml”, “yaml”}, the backend dataset instance will be created accordingly to save/load as an MLflow artifact.
If set to a Kedro DataSet object or a dictionary, it will be used as the backend dataset to save/load as an MLflow artifact.
If set to None (default), MLflow logging will be skipped.
Regarding all the options, see the API document
Kedro Hooks
pipelinex.MLflowBasicLoggerHook: Configures MLflow logging and logs duration time for the pipeline to MLflow.pipelinex.MLflowArtifactsLoggerHook: Logs artifacts of specified file paths and dataset names to MLflow.pipelinex.MLflowDataSetsLoggerHook: Logs datasets of (list of) float/int and str classes to MLflow.pipelinex.MLflowTimeLoggerHook: Logs duration time for each node (task) to MLflow and optionally visualizes the execution logs as a Gantt chart byplotly.figure_factory.create_ganttifplotlyis installed.pipelinex.AddTransformersHook: Adds Kedro transformers such as:pipelinex.MLflowIOTimeLoggerTransformer: Logs duration time to load and save each dataset with args:
Regarding all the options, see the API document
MLflow-ready Kedro projects can be generated by the Kedro starters (Cookiecutter template) which include the following example config:
# catalog.yml # Write a pickle file & upload to MLflow model: type: pipelinex.MLflowDataSet dataset: pkl # Write a csv file & upload to MLflow pred_df: type: pipelinex.MLflowDataSet dataset: csv # Write an MLflow metric score: type: pipelinex.MLflowDataSet dataset: m
# catalog.py (alternative to catalog.yml) catalog_dict = { "model": MLflowDataSet(dataset="pkl"), # Write a pickle file & upload to MLflow "pred_df": MLflowDataSet(dataset="csv"), # Write a csv file & upload to MLflow "score": MLflowDataSet(dataset="m"), # Write an MLflow metric }
# mlflow_config.py import pipelinex mlflow_hooks = ( pipelinex.MLflowBasicLoggerHook( enable_mlflow=True, # Enable configuring and logging to MLflow uri="sqlite:///mlruns/sqlite.db", experiment_name="experiment_001", artifact_location="./mlruns/experiment_001", offset_hours=0, # Specify the offset hour (e.g. 0 for UTC/GMT +00:00) to log in MLflow ), # Configure and log duration time for the pipeline pipelinex.MLflowArtifactsLoggerHook( enable_mlflow=True, # Enable logging to MLflow filepaths_before_pipeline_run=[ "conf/base/parameters.yml" ], # Optionally specify the file paths to log before pipeline is run filepaths_after_pipeline_run=[ "data/06_models/model.pkl" ], # Optionally specify the file paths to log after pipeline is run ), # Log artifacts of specified file paths and dataset names pipelinex.MLflowDataSetsLoggerHook( enable_mlflow=True, # Enable logging to MLflow ), # Log output datasets of (list of) float, int, and str classes pipelinex.MLflowTimeLoggerHook( enable_mlflow=True, # Enable logging to MLflow ), # Log duration time to run each node (task) pipelinex.AddTransformersHook( transformers=[ pipelinex.MLflowIOTimeLoggerTransformer( enable_mlflow=True ) # Log duration time to load and save each dataset ], ), # Add transformers )
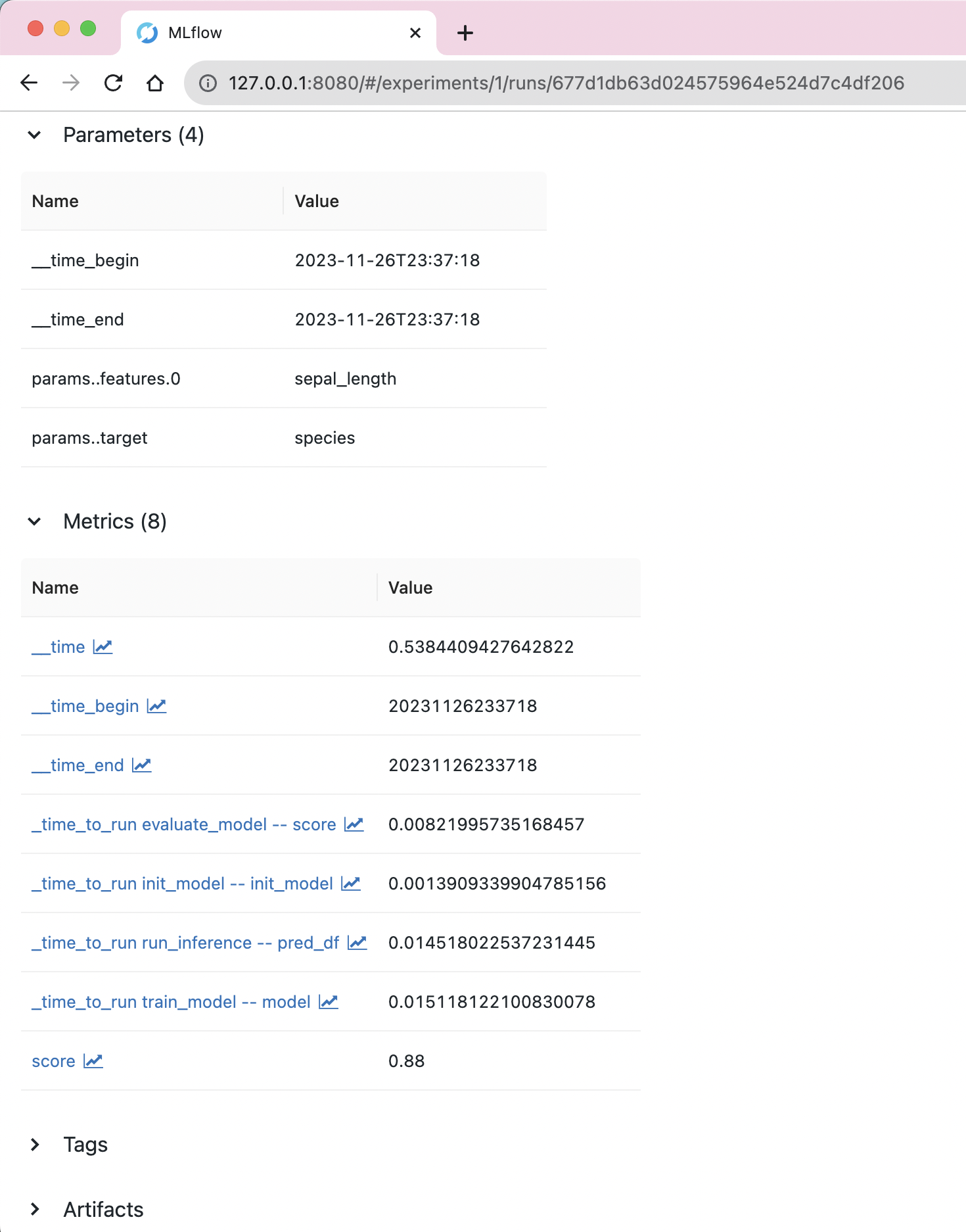 Logged metrics shown in MLflow's UI
Logged metrics shown in MLflow's UI
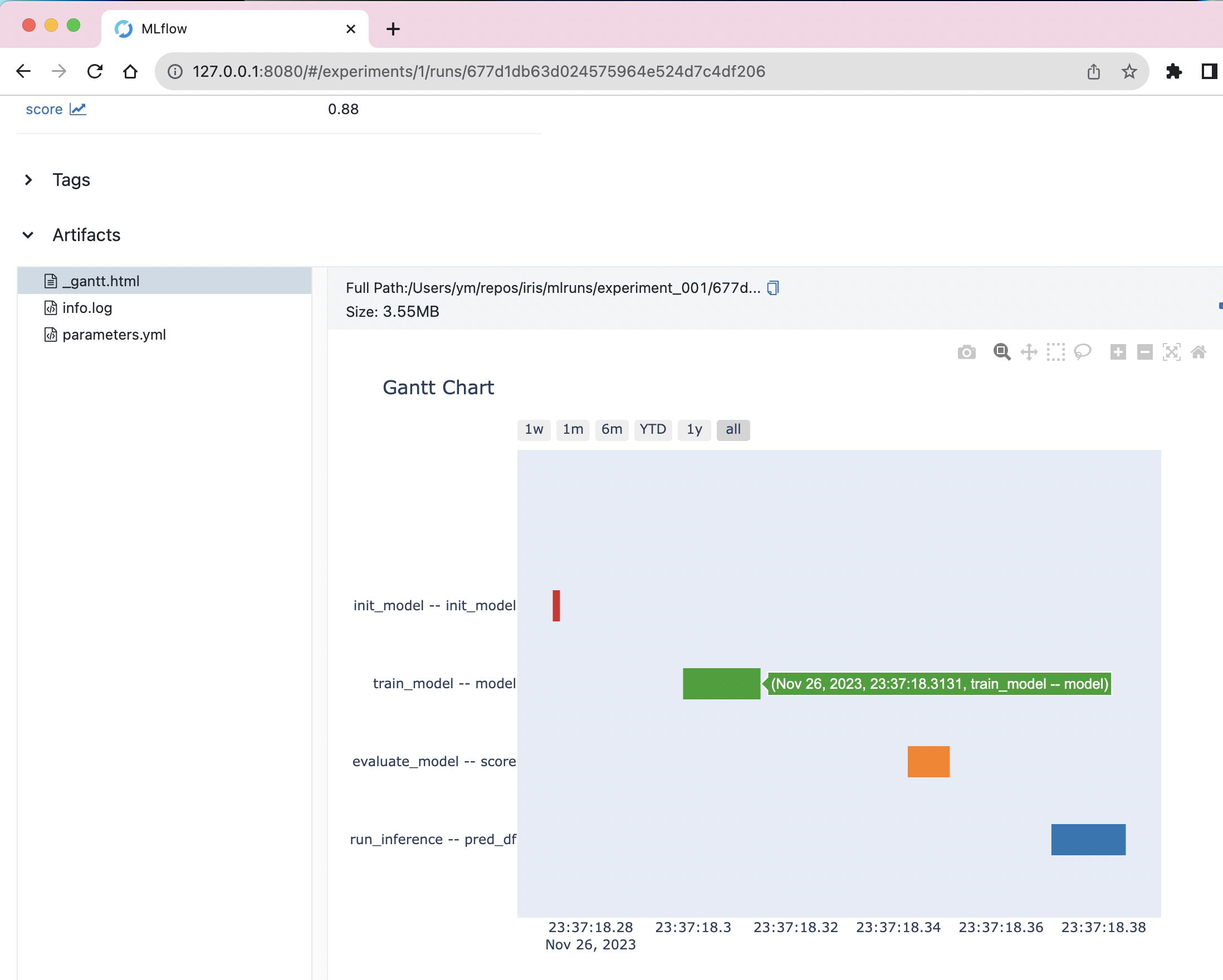 Gantt chart for execution time, generated using Plotly, shown in MLflow's UI
Gantt chart for execution time, generated using Plotly, shown in MLflow's UI
Comparison with kedro-mlflow package¶
Both PipelineX and kedro-mlflow provide integration of MLflow to Kedro. Here are the comparisons.
Features supported by both PipelineX and kedro-mlflow
Kedro DataSets and Hooks to log (save/upload) artifacts, parameters, and metrics to MLflow.
Truncate MLflow parameter values to 250 characters to avoid error due to MLflow parameter length limit.
Dict values can be flattened using dot (“.”) as the separator to log each value inside the dict separately.
Features supported by only PipelineX
[Time logging] Option to log execution time for each task (Kedro node) as MLflow metrics
[Gantt logging] Option to log Gantt chart HTML file that visualizes execution time using Plotly as an MLflow artifact (inspired by Apache Airflow)
[Automatic backend Kedro DataSets for common artifacts] Option to specify a common file extension ({“json”, “csv”, “xls”, “parquet”, “png”, “jpg”, “jpeg”, “img”, “pkl”, “txt”, “yml”, “yaml”}) so the Kedro DataSet object will be created behind the scene instead of manually specifying a Kedro DataSet including filepath in the catalog (inspired by Kedro Wings).
[Automatic logging for MLflow parameters and metrics] Option to log each dataset not listed in the catalog as MLflow parameter or metric, instead of manually specifying a Kedro DataSet in the catalog.
If the data type is either {float, int}, the value will be saved/loaded as an MLflow metric.
If the data type is either {str, list, tuple, set}, the value will be saved/load as an MLflow parameter.
If the data type is dict, the value will be flattened with dot (“.”) as the separator and then saved/loaded as either an MLflow metric or parameter based on each data type as explained above.
For example,
"data_loading_config": {"train": {"batch_size": 32}}will be logged as MLflow metric of"data_loading_config.train.batch_size": 32)
[Flexible config per DataSet] For each Kedro DataSet, it is possible to configure differently. For example, a dict value can be logged as an MLflow parameter (string) as is while another one can be logged as an MLflow metric after being flattened.
[Direct artifact logging] Option to specify the paths of any data to log as MLflow artifacts after Kedro pipeline runs without using a Kedro DataSet, which is useful if you want to save local files (e.g. info/warning/error log files, intermediate model weights saved by Machine Learning packages such as PyTorch and TensorFlow, etc.)
[Environment Variable logging] Option to log Environment Variables
[Downloading] Option to download MLflow artifacts, params, metrics from an existing MLflow experiment run using the Kedro DataSet
[Up to date] Support for Kedro 0.17.0 (released in Dec 2020) or later
Features provided by only kedro-mlflow
A wrapper for MLflow’s
log_modelConfigure MLflow logging in a YAML file
Option to use MLflow tag or raise error if MLflow parameter values exceed 250 characters